
본 문서는 어서와! 자료구조와 알고리즘은 처음이지? 강의를 보고 제 주관대로 정리한 글입니다.
트리 (Tree)
- 정점(Node)과 간선(Edge)을 이용해서 데이터의 배치 형태를 추상화한 자료 구조
트리 용어
- 제일 위가 루트 (Root) 노드
- 제일 아래가 리프 (Leaf) 노드
- 루트도 리프도 아닌 내부 (Internal) 노드
- 바로 위는 부모 (Parent) 노드
- 바로 아래는 자식 (Child) 노드
- 같은 부모를 두면 형제 (Sibling) 노드
- 부모와 그 부모 노드들은 조상 (Ancestor) 노드
- 자식과 그 자식 노드들은 후손 (Descendant) 노드
수준 (Level)
- 루트 노드의 Level은 0 또는 1부터 시작할 수 있는데 여기서는 0부터 시작함
- 루트 노드의 Level이 0, 아래로 내려갈 수록 Level이 1씩 높아짐
- Level이 루트 노드로부터 특정 노드까지의 간선의 수라고 정의하면 루트 노드를 0으로 하는 게 편함
높이 (Height)
- 깊이(Depth)라고도 함
- 트리의 높이 (Height) = 최대 수준 (Level) + 1
부분 트리 (Subtree)
- 전체 트리에서 부분을 차지하는 트리
노드의 차수 (Degree)
- 자식(서브트리)의 수
- 리프 노드는 자식이 없어서 차수가 0
이진 트리 (Binary Tree)
- 모든 노드의 차수가 2 이하인 트리
- 재귀적으로 정의할 수 있음
- 빈 트리(Empty Tree)이거나
- 루트 노드 + 왼쪽 서브트리 + 오른쪽 서브트리
- 이때 왼쪽과 오른쪽 서브트리 또한 이진 트리

포화 이진 트리 (Full Binary Tree)
- 모든 레벨에서 노드들이 모두 채워져 있는 이진 트리
- 높이가 k라면, 노드의 개수가 2k-1인 이진 트리

완전 이진 트리 (Complete Binary Tree)
- 높이 k인 완전 이진 트리
- 레벨 k-2까지는 모든 노드가 2개의 자식을 가진 포화 이진 트리
- 레벨 k-1에서는 왼쪽부터 노드가 순차적으로 채워져 있는 이진 트리

이진 트리 구현
연산의 정의
size()- 현재 트리에 포함되어 있는 노드의 수- 전체 이진 트리의 size() = 왼쪽 서브트리의 size() + 오른쪽 서브트리의 size() + 1 (자기 자신)
depth()- 현재 트리의 깊이 (또는 높이; height)- 전체 이진 트리의 depth() = 왼쪽 서브트리의 depth()와 오른쪽 서브트리의 depth() 중 더 큰 것 + 1
- 순회 (Traversal)
- 깊이 우선 순회 (Depth First Traversal)
- 중위 순회 (In-order Traversal)
- 전위 순회 (Pre-order Traversal)
- 후위 순회 (Post-order Traversal)
- 넓이 우선 순회 (Breadth First Traversal)
- 깊이 우선 순회 (Depth First Traversal)
중위 순회 (In-order Traversal)
- 왼쪽 서브트리
- 자기 자신
- 오른쪽 서브트리

전위 순회 (Pre-order Traversal)
- 자기 자신
- 왼쪽 서브트리
- 오른쪽 서브트리
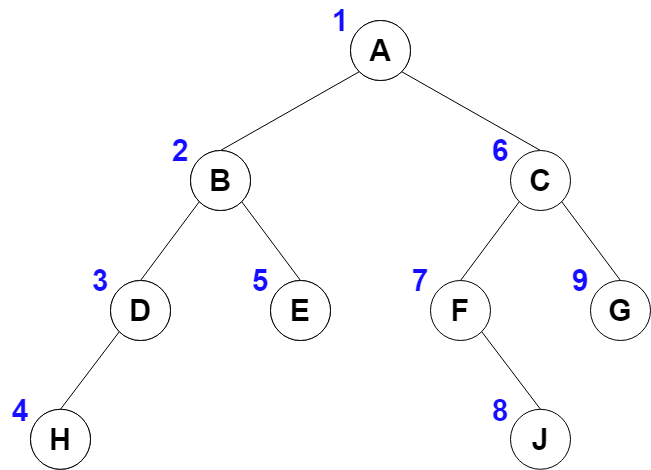
후위 순회 (Post-order Traversal)
- 왼쪽 서브트리
- 오른쪽 서브트리
- 자기 자신

넓이 우선 순회 (Breadth First Traversal)
- 원칙
- 수준(Level)이 낮은 노드를 우선으로 방문
- 같은 수준의 노드들 사이에는,
- 부모 노드의 방문 순서에 따라 방문
- 왼쪽 자식을 오른쪽 자식보다 먼저 방문
- 재귀적 방법이 적합하지 않음
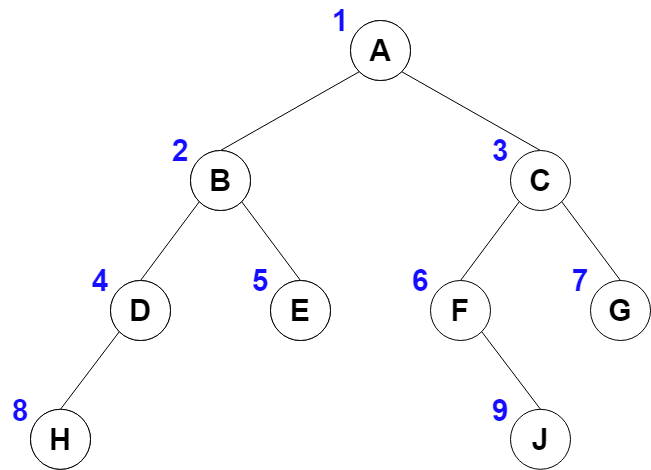
넓이 우선 순회 알고리즘 설계
- 한 노드를 방문했을 때, 나중에 방문할 노드들을 순서대로 기록해 두어야 함
- 큐가 유리
- (초기화) traversal <- 빈 리스트, q <- 빈 큐
- 빈 트리가 아니면, root node를 q에 추가 (enqueue)
- q가 비어 있지 않은 동안
- node <- q에서 원소를 추출 (dequeue)
- node를 방문
- node의 왼쪽, 오른쪽 자식 (있으면) 들을 q에 추가
- q가 빈 큐가 되면 모든 노드 방문 완료
큐 관련 코드는 array_queue.py 참고
class Node:
def __init__(self, item):
self.data = item
self.left = None
self.right = None
def size(self):
l = self.left.size() if self.left else 0
r = self.right.size() if self.right else 0
return l + r + 1
def depth(self):
l = self.left.depth() if self.left else 0
r = self.right.depth() if self.right else 0
return max(l, r) + 1
def inorder(self):
traversal = []
if self.left:
traversal += self.left.inorder()
traversal.append(self.data)
if self.right:
traversal += self.right.inorder()
return traversal
def preorder(self):
traversal = [self.data]
if self.left:
traversal += self.left.preorder()
if self.right:
traversal += self.right.preorder()
return traversal
def postorder(self):
traversal = []
if self.left:
traversal += self.left.postorder()
if self.right:
traversal += self.right.postorder()
traversal.append(self.data)
return traversal
class BinaryTree:
def __init__(self, r):
self.root = r
def size(self):
return self.root.size() if self.root else 0
def depth(self):
return self.root.depth() if self.root else 0
def inorder(self):
return self.root.inorder() if self.root else []
def preorder(self):
return self.root.preorder() if self.root else []
def postorder(self):
return self.root.postorder() if self.root else []
def bft(self):
traversal = []
q = ArrayQueue()
if self.root:
q.enqueue(self.root)
while not q.is_empty():
node = q.dequeue()
traversal.append(node.data)
if node.left:
q.enqueue(node.left)
if node.right:
q.enqueue(node.right)
return traversal이진 탐색 트리 (Binary Search Tree)
- 모든 노드에 대해서
- 왼쪽 서브트리에 있는 데이터는 모두 현재 노드의 값보다 작고
- 오른쪽 서브트리에 있는 데이터는 모두 현재 노드의 값보다 큰
- 성질을 만족하는 이진 트리
- (중복되는 데이터 원소는 없는 것으로 가정)

(정렬된) 배열을 이용한 이진 탐색과 비교
- 장점
- 데이터 원소의 추가, 삭제가 용이
- 단점
- 공간 소요가 큼
항상 O(logn)의 탐색 복잡도는 아닐 수 있음
- 공간 소요가 큼
데이터 표현 - 각 노드는 (key, value)의 쌍으로
- 키를 이용해서 검색 가능
- 보다 복잡한 데이터 레코드로 확장 가능
연산 정의
insert(key, data)- 데이터 원소 추가- 입력 인자: 키, 데이터 원소
- 리턴: 없음
remove(key)- 특정 원소 삭제 (아래서 추가 설명)lookup(key)- 특정 원소 검색- 입력 인자: 찾으려는 대상 키
- 리턴: 찾은 노드와 그것의 부모 노드 (각각 없으면 None으로)
inorder()- 키의 순서대로 데이터 원소를 나열min(),max()- 최소 키, 최대 키를 가지는 원소를 각각 탐색
이진 탐색 트리에서 원소 삭제
- 키(Key)를 이용해서 노드를 찾는다.
- 해당 키의 노드가 없으면, 삭제할 것도 없음
- 찾은 노드의 부모 노드도 알고 있어야 함(아래 2번 때문)
- 찾은 노드를 제거하고도 이진 탐색 트리 성질을 만족하도록 트리의 구조를 정리한다.
remove(key)- 특정 원소를 트리로부터 삭제- 입력: 키 (key)
- 출력: 삭제한 경우 True, 해당 키의 노드가 없는 경우 False
이진 탐색 트리 구조의 유지
- 삭제되는 노드가
- 리프 노드인 경우
- 그냥 그 노드를 없애면 됨
- 부모 노드의 링크를 조정 (좌? 우?)
- 자식을 하나 가지고 있는 경우
- 삭제되는 노드 자리에 그 자식을 대신 배치
- 자식이 왼쪽? 오른쪽?
- 부모 노드의 링크를 조정 (좌? 우?)
- 삭제되는 노드 자리에 그 자식을 대신 배치
- 자식을 둘 가지고 있는 경우
- 삭제되는 노드보다 바로 다음 (큰 or 작은) 키를 가지는 노드를 찾아 그 노드를 삭제되는 노드 자리에 대신 배치하고 이 노드를 대신 삭제
- 리프 노드인 경우
class Node:
def __init__(self, key, data):
self.key = key
self.data = data
self.left = None
self.right = None
def inorder(self):
traversal = []
if self.left:
traversal += self.left.inorder()
traversal.append(self)
if self.right:
traversal += self.right.inorder()
return traversal
def min(self):
return self.left.min() if self.left else self
def max(self):
return self.right.max() if self.right else self
def lookup(self, key, parent=None):
if key < self.key:
return self.left.lookup(key, self) if self.left else None, None
if key > self.key:
return self.right.lookup(key, self) if self.right else None, None
return self, parent
def insert(self, key, data):
if key < self.key:
if self.left:
self.left.insert(key, data)
else:
self.left = Node(key, data)
elif key > self.key:
if self.right:
self.right.insert(key, data)
else:
self.right = Node(key, data)
else:
raise KeyError('중복된 키는 허용하지 않습니다.')
def count_children(self):
count = 0
if self.left:
count += 1
if self.right:
count += 1
return count
class BinarySearchTree:
def __init__(self):
self.root = None
def inorder(self):
return self.root.inorder() if self.root else []
def min(self):
return self.root.min() if self.root else None
def max(self):
return self.root.max() if self.root else None
def lookup(self, key):
return self.root.lookup(key) if self.root else None, None
def insert(self, key, data):
if self.root:
self.root.insert(key, data)
else:
self.root = Node(key, data)
def remove(self, key):
node, parent = self.lookup(key)
if node:
children_count = node.count_children()
# The simplest case of no children
if children_count == 0:
# 만약 parent 가 있으면
# node 가 왼쪽 자식인지 오른쪽 자식인지 판단하여
# parent.left 또는 parent.right 를 None 으로 하여
# leaf node 였던 자식을 트리에서 끊어내어 없앱니다.
if parent:
if parent.left is node:
parent.left = None
else:
parent.right = None
# 만약 parent 가 없으면 (node 는 root 인 경우)
# self.root 를 None 으로 하여 빈 트리로 만듭니다.
else:
self.root = None
# When the node has only one child
elif children_count == 1:
# 하나 있는 자식이 왼쪽인지 오른쪽인지를 판단하여
# 그 자식을 어떤 변수가 가리키도록 합니다.
if node.left:
child = node.left
else:
child = node.right
# 만약 parent 가 있으면
# node 가 왼쪽 자식인지 오른쪽 자식인지 판단하여
# 위에서 가리킨 자식을 대신 node 의 자리에 넣습니다.
if parent:
if parent.left is node:
parent.left = child
else:
parent.right = child
# 만약 parent 가 없으면 (node 는 root 인 경우)
# self.root 에 위에서 가리킨 자식을 대신 넣습니다.
else:
self.root = child
# When the node has both left and right children
else:
parent = node
successor = node.right
# parent 는 node 를 가리키고 있고,
# successor 는 node 의 오른쪽 자식을 가리키고 있으므로
# successor 로부터 왼쪽 자식의 링크를 반복하여 따라감으로써
# 순환문이 종료할 때 successor 는 바로 다음 키를 가진 노드를,
# 그리고 parent 는 그 노드의 부모 노드를 가리키도록 찾아냅니다.
while successor.left:
parent = successor
successor = successor.left
# 삭제하려는 노드인 node 에 successor 의 key 와 data 를 대입합니다.
node.key = successor.key
node.data = successor.data
# 이제, successor 가 parent 의 왼쪽 자식인지 오른쪽 자식인지를 판단하여
# 그에 따라 parent.left 또는 parent.right 를
# successor 가 가지고 있던 (없을 수도 있지만) 자식을 가리키도록 합니다.
if parent.left is successor:
parent.left = successor.right
else:
parent.right = successor.right
return True
else:
return False이진 탐색 트리가 효율적이지 못한 경우
- 한 쪽으로 치우친 이진 탐색 트리의 경우
- 선형 탐색과 비슷함

보다 나은 성능을 보이는 이진 탐색 트리들
- 높이의 균형을 유지함으로써 O(logn)의 탐색 복잡도 보장
- 삽입, 삭제 연산이 보다 복잡
- e.g., AVL tree, Red-Black Tree
'자료구조와 알고리즘 > 어서와! 자료구조와 알고리즘은 처음이지?' 카테고리의 다른 글
| [어서와! 자료구조와 알고리즘은 처음이지?] 08. 힙 (0) | 2022.07.01 |
|---|---|
| [어서와! 자료구조와 알고리즘은 처음이지?] 06. 큐 (0) | 2022.06.26 |
| [어서와! 자료구조와 알고리즘은 처음이지?] 05. 스택 (0) | 2022.06.24 |
| [어서와! 자료구조와 알고리즘은 처음이지?] 04. 연결 리스트 (0) | 2022.06.24 |
| [어서와! 자료구조와 알고리즘은 처음이지?] 03. 알고리즘 복잡도 (0) | 2022.06.23 |